
|
Unnat Jain*,
Luca Weihs*,
Eric Kolve,
Ali Farhadi,
Svetlana Lazebnik, Aniruddha Kembhavi, Alexander Schwing |
|
University of Illinois at Urbana-Champaign,
Allen Institute for AI, University of Washington To appear at ECCV 2020 (Spotlight) |
|
|
|
|
|
|
|
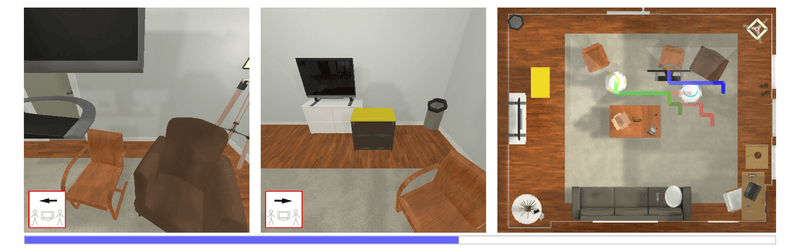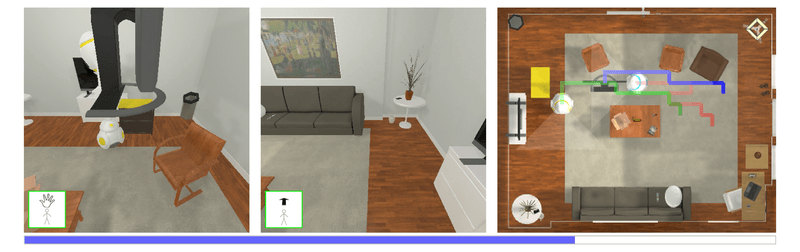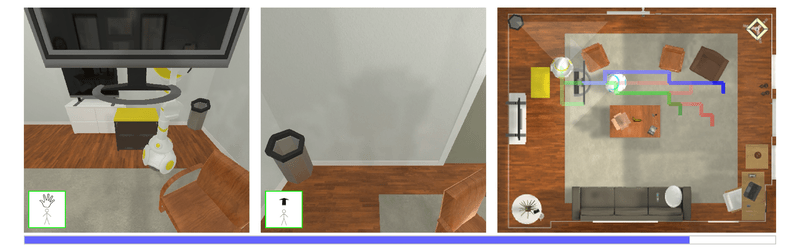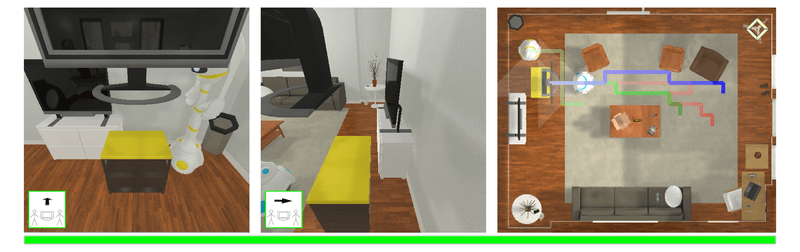
| Autonomous agents must learn to collaborate. It is not scalable to develop a new centralized agent every time a task's difficulty outpaces a single agent's abilities. While multi-agent collaboration research has flourished in gridworld-like environments, relatively little work has considered visually rich domains. Addressing this, we introduce the novel task FurnMove in which agents work together to move a piece of furniture through a living room to a goal. Unlike existing tasks, FurnMove requires agents to coordinate at every timestep. We identify two challenges when training agents to complete FurnMove: existing decentralized action sampling procedures do not permit expressive joint action policies and, in tasks requiring close coordination, the number of failed actions dominates successful actions. To confront these challenges we introduce SYNC-policies (synchronize your actions coherently) and CORDIAL (coordination loss). Using SYNC-policies and CORDIAL, our agents achieve a 58% completion rate on FurnMove, an impressive absolute gain of 25 percentage points over competitive decentralized baselines. |
|
|
SYNC-Policies |
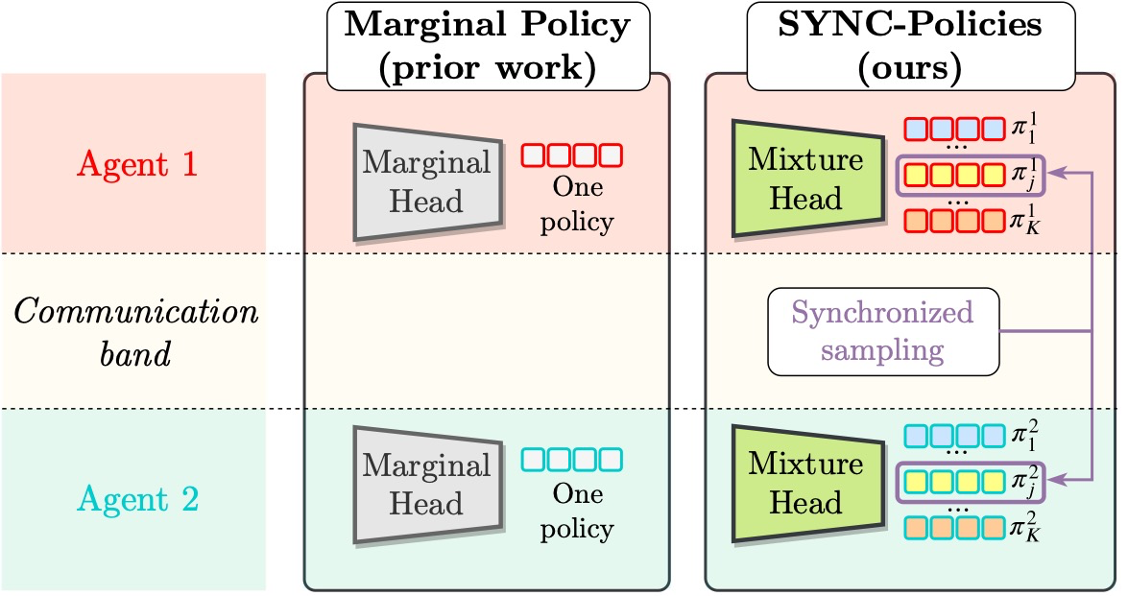
| Previous multi-agent RL methods consist of a communicative backbone followed by a single marginal policy per agent. This limits the joint policy that these methods can capture. The joint policy is a rank one matrix, particularly, the outer product of the marginal policies of the two agents. For the general case of N agents, this is a rank one tensor. $$\Pi_{\text{marginal}} = \pi^1\otimes\cdots \otimes \pi^N$$ We leverage the communication band to move beyond this rank one joint policy. SYNC policies weave m marginal policies per agent using synchronized sampling (details in the paper). This leads to a more expressive joint policy as a mixture of marginal policies. For the N agent setup, the joint policy becomes: $$\Pi_{\text{SYNC}} = \sum_{j=1}^m \alpha_j \cdot \pi^1_{j} \otimes \ldots \otimes \pi^N_{j}$$ |
|
Explanatory videos |
|
|
|
|
|
A detailed (10 min) video, corresponding slides: [Detailed slides]. |
|
|
Qualitative Results |
| This video highlighting policy roll-outs of marginal policies vs. SYNC-policies. Additionally, we include a way to experience what the agents 'tell' each other (enable audio for this clip). |
|
|
References |
| (1) Unnat Jain*, Luca Weihs*, Eric Kolve, Ali Farhadi, Svetlana Lazebnik, Aniruddha Kembhavi, Alexander Schwing. A Cordial Sync: Going Beyond Marginal Policies For Multi-Agent Embodied Tasks. In ECCV 2020 [Bibtex] |

|
| (2) Unnat Jain*, Luca Weihs*, Eric Kolve, Mohammad Rategari, Svetlana Lazebnik, Ali Farhadi, Alexander Schwing, Aniruddha Kembhavi. Two Body Problem: Collaborative Visual Task Completion. In CVPR 2019 [Bibtex] |

|
Acknowledgements |
| This material is based upon work supported in part by the National Science Foundation under Grants No. 1563727, 1718221, 1637479, 165205, 1703166, Samsung, 3M, Sloan Fellowship, NVIDIA Artificial Intelligence Lab, Allen Institute for AI, Amazon, and AWS Research Awards. UJ is thankful to Thomas & Stacey Siebel Foundation for Siebel Scholars Award. We thank Mitchell Wortsman and Kuo-Hao Zeng for their insightful suggestions on how to clarify and structure this work. |
| Website adapted from Jingxiang, Richard and Deepak. |