Embodied Agents Struggle to Learn From Terminal Rewards
|
Unnat Jain,
Iou-Jen Liu,
Svetlana Lazebnik,
Aniruddha Kembhavi, Luca Weihs, Alexander Schwing |
|
University of Illinois at Urbana-Champaign, Allen Institute for AI ICCV 2021 |
|
|
|
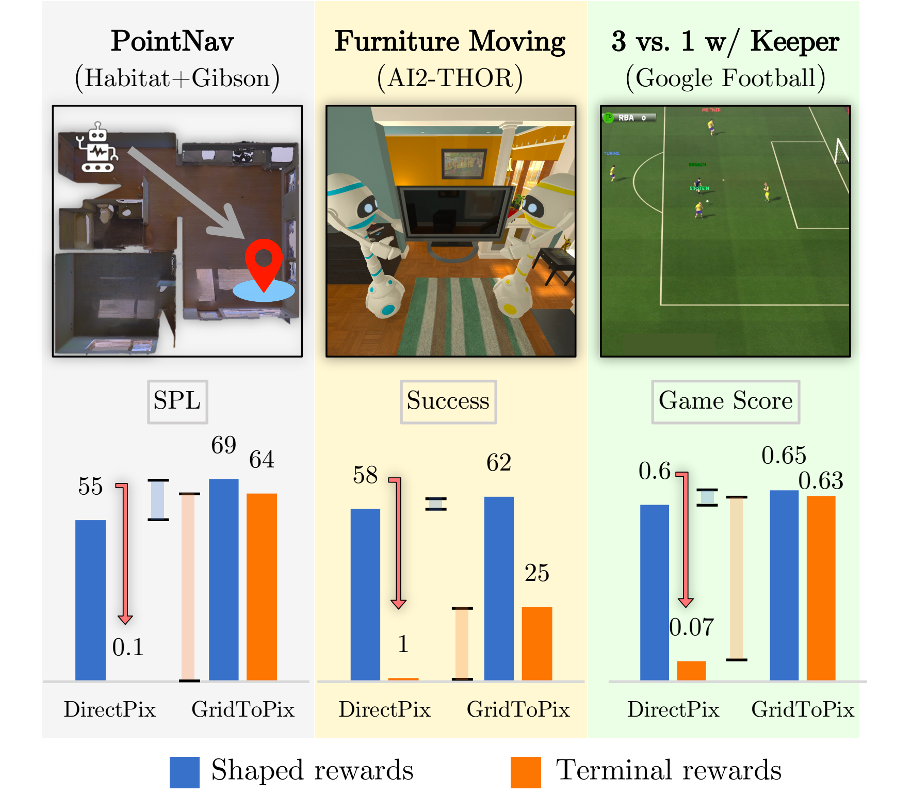
| While deep reinforcement learning (RL) promises freedom from hand-labeled data, great successes, especially for Embodied AI, require significant work to create supervision via carefully shaped rewards. Indeed, without shaped rewards, i.e., with only terminal rewards, present-day Embodied AI results degrade significantly across Embodied AI problems from single-agent Habitat-based PointGoal Navigation and two-agent AI2-THOR-based Furniture Moving to three-agent Google Football-based 3 vs. 1 with Keeper. As training from shaped rewards doesn’t scale to more realistic tasks, the community needs to improve the success of training with terminal rewards. For this we propose GridToPix: 1) train agents with terminal rewards in gridworlds that generically mirror Embodied AI environments, i.e., they are independent of the task; 2) distill the learned policy into agents that reside in complex visual worlds. Despite learning from only terminal rewards with identical models and RL algorithms, GridToPix significantly improves results across the three diverse tasks. |
|
|
Embodied Agents Struggle to Learn From Terminal Rewards |
|
|
| We consider a variety of challenging tasks in three diverse simulators – single-agent PointGoal Navigation in Habitat (SPL drops from 55 to 0), two-agent Furniture Moving in AI2-THOR (success drops from 58% to 1%), and three-agent 3 vs. 1 with Keeper in the Google Research Football Environment (game score drops from 0.6 to 0.1). Given only terminal rewards, we find that performance of these modern methods degrades drastically, as summarized above. Often, no meaningful policy is learned despite training for millions of steps. These results are eye-opening and a reminder that we are still ways off in our pursuit of embodied agents that can learn skills with minimal supervision, i.e., supervision in the form of only terminal rewards. |
GridToPix |
|
|
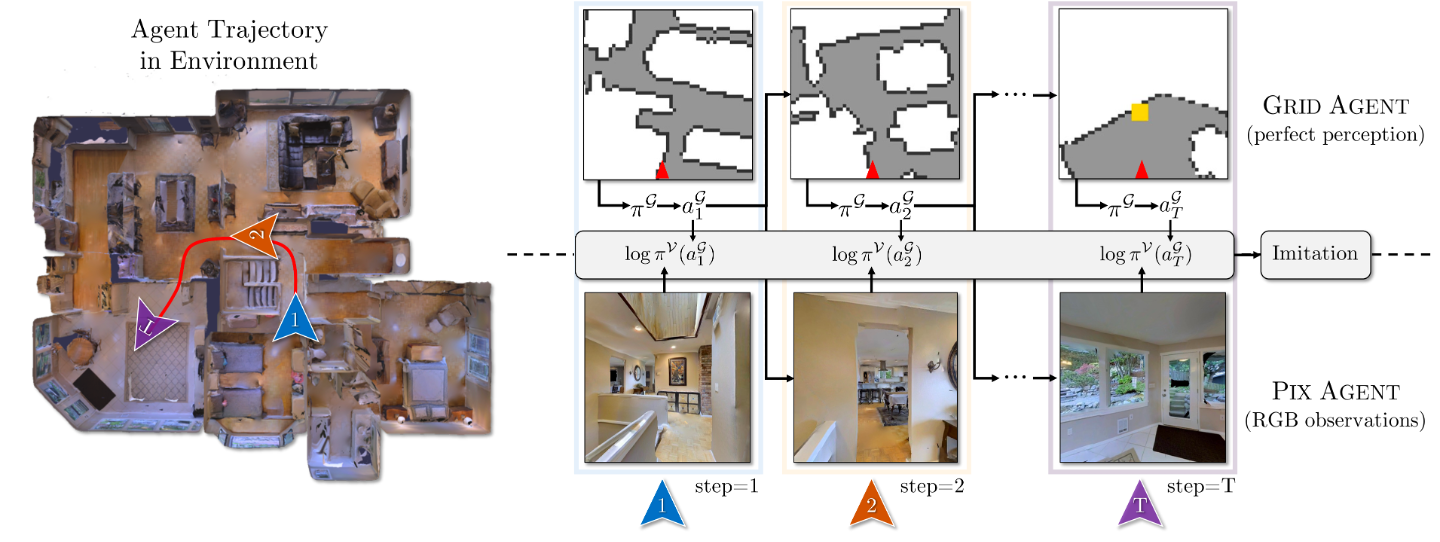
GridToPix is a
training routine for embodied agents that decouples the joint
goal of planning from visual input into two manageable
pieces. Specifically, using general-purpose gridworld environments
which generically mirror the embodied environments
of interest, we first train a gridworld agent for the
desired task. Within a gridworld, an agent has perfect visual
capabilities, allowing learning algorithms to focus on
long-horizon planning given only terminal rewards. This
capable gridworld agent is then used to supervise an agent
within a far more complex visual world.
Results: Across tasks, as summarized in Fig. 1, we observe that GridToPix significantly outperforms directly comparable (i.e. using identical model architectures) methods when training visual agents using terminal rewards: for PointGoal Navigation the SPL metric improves from 0 to 64; for Furniture Moving success improves from 1% to 25%; for 3 vs. 1 with Keeper the game score improves from 0.1 to 0.63. GridToPix even improves benchmarks when trained with carefully shaped rewards. This finding is analogous to the progress made by weakly supervised computer vision approaches which inch towards benchmarks set by fully supervised methods. |
References |
| (1) Unnat Jain, Iou-Jen Liu, Svetlana Lazebnik, Aniruddha Kembhavi, Luca Weihs*, Alexander Schwing*. GridToPix: Training Embodied Agents with Minimal Supervision. In ICCV 2021 [Bibtex] |

|
Acknowledgements |
| This work is supported in part by NSF under Grant #1718221, 2008387, 2045586, MRI #1725729, and NIFA award 2020-67021-32799. We thank Anand Bhattad, Angel X. Chang, Manolis Savva, Martin Lohmann, and Tanmay Gupta for thoughtful discussions and valuable input. |
| Website source |