|
Luca Weihs*,
Unnat Jain*,
Iou-Jen Liu,
Jordi Salvador,
Svetlana Lazebnik, Aniruddha Kembhavi, Alexander Schwing |
|
* equal contribution by LW and UJ
Allen Institute for AI, University of Illinois at Urbana-Champaign, University of Washington NeurIPS 2021 |
|
|
|
|
|
|
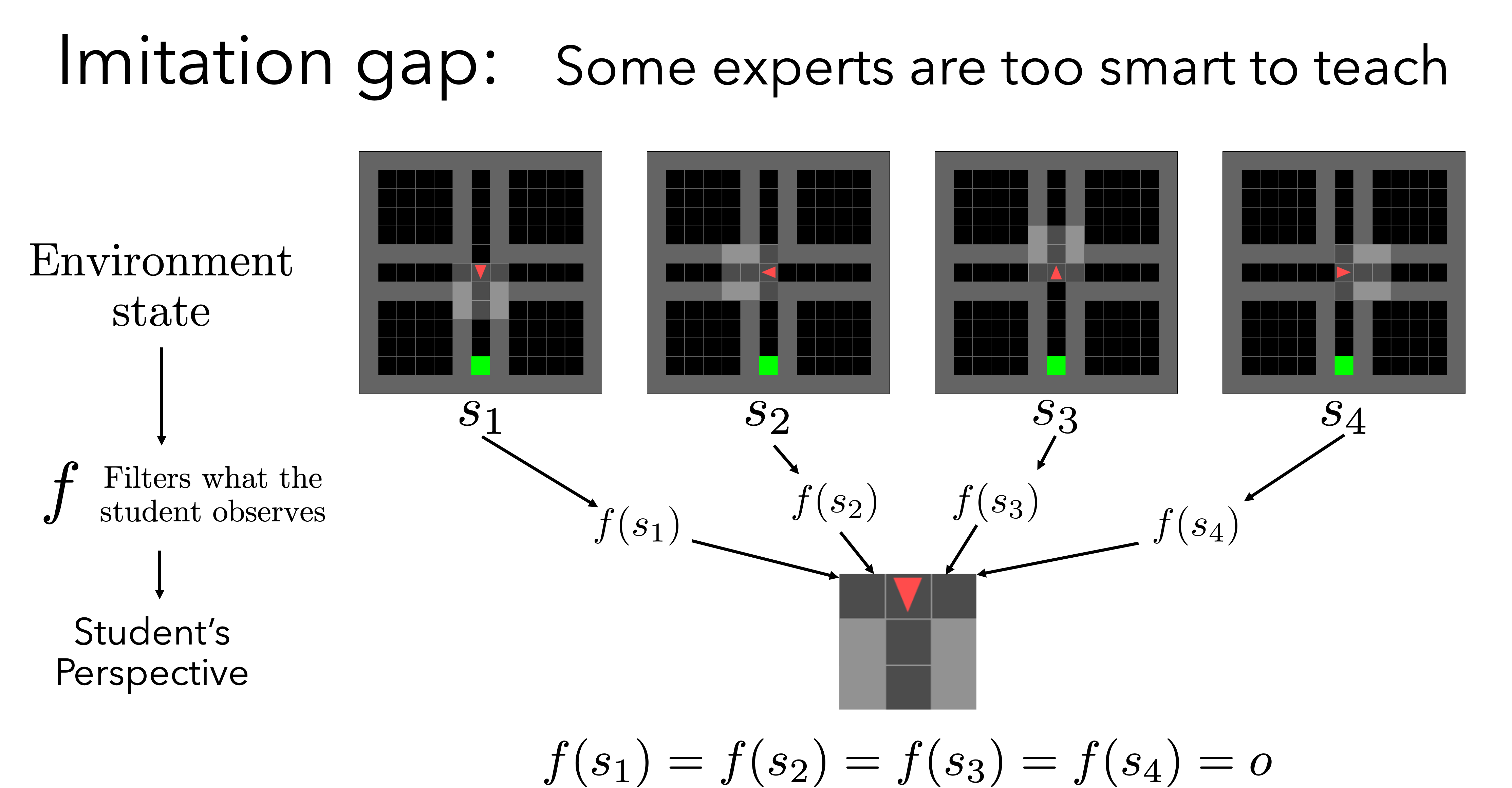
| In practice, imitation learning is preferred over pure reinforcement learning whenever it is possible to design a teaching agent to provide expert supervision. However, we show that when the teaching agent makes decisions with access to privileged information that is unavailable to the student, this information is marginalized during imitation learning, resulting in an "imitation gap" and, potentially, poor results. Prior work bridges this gap via a progression from imitation learning to reinforcement learning. While often successful, gradual progression fails for tasks that require frequent switches between exploration and memorization. To better address these tasks and alleviate the imitation gap we propose 'Adaptive Insubordination' (ADVISOR). ADVISOR dynamically weights imitation and reward-based reinforcement learning losses during training, enabling on-the-fly switching between imitation and exploration. On a suite of challenging tasks set within gridworlds, multi-agent particle environments, and high-fidelity 3D simulators, we show that on-the-fly switching with ADVISOR outperforms pure imitation, pure reinforcement learning, as well as their sequential and parallel combinations. |
Adaptive Insubordination (ADVISOR) |
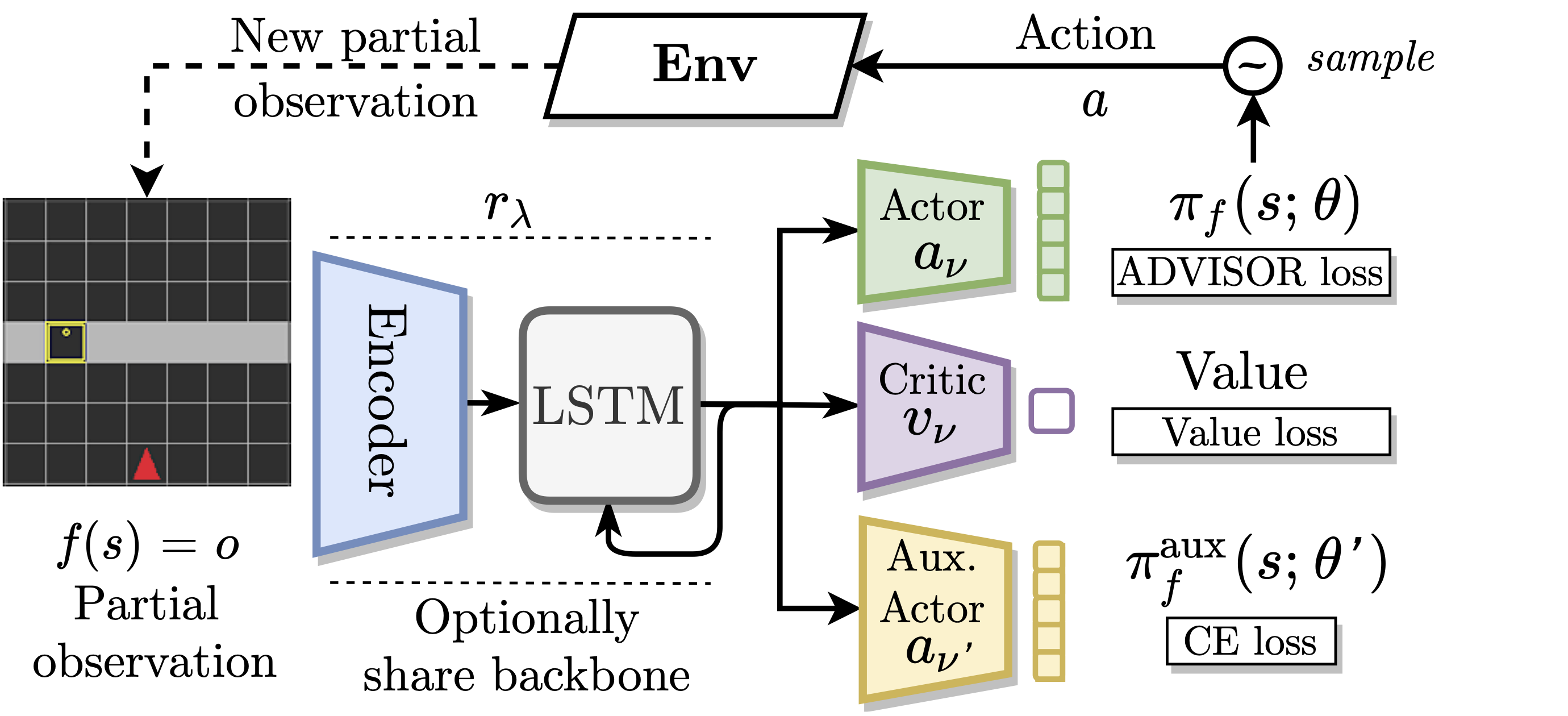
| During training we use an auxiliary actor which judges whether the current observation is better treated using an IL or a RL loss. For this, the auxiliary actor attempts to reproduce the expert’s action from the perspective of the learning agent at every step. Intuitively, the weight corresponding to the IL loss is large when the auxiliary actor can reproduce the expert’s action with high confidence and is otherwise small. As we show empirically, ADVISOR combines the benefits of IL and RL while avoiding the pitfalls of either method alone. |
|
Tasks |
| We study the benefits of ADVISOR on thirteen tasks, including a 2D “lighthouse” gridworld, a suite of tasks set within the MiniGrid environment (Chevalier-Boisvert et al. 2018), Cooperative Navigation with limited range (CoopNav) in OpenAI multi-agent particle environment (Lowe et al. 2019), and two navigational tasks set in 3D, high visual fidelity, simulators of real-world living environments -- PointNav in AIHabitat (Savva et al. 2019) and ObjectNav in RoboTHOR (Deitke et al. 2020). For more details, please see our paper. |
|
More resources |
|
|
|
|
References |
| (1) Luca Weihs*, Unnat Jain*, Iou-Jen Liu, Jordi Salvador, Svetlana Lazebnik, Aniruddha Kembhavi, Alexander Schwing. Bridging the Imitation Gap by Adaptive Insubordination. In NeurIPS 2021 [Bibtex] |

|
Acknowledgements |
| This material is based upon work supported in part by the National Science Foundation under Grants No. 1563727, 1718221, 1637479, 165205, 1703166, Samsung, 3M, Sloan Fellowship, NVIDIA Artificial Intelligence Lab, Allen Institute for AI, Amazon, AWS Research Awards, and Siebel Scholars Award. We thank Nan Jiang and Tanmay Gangwani for feedback on this work. |
| Website source |